Relationship among RDMS, NoSQL and MapReduce
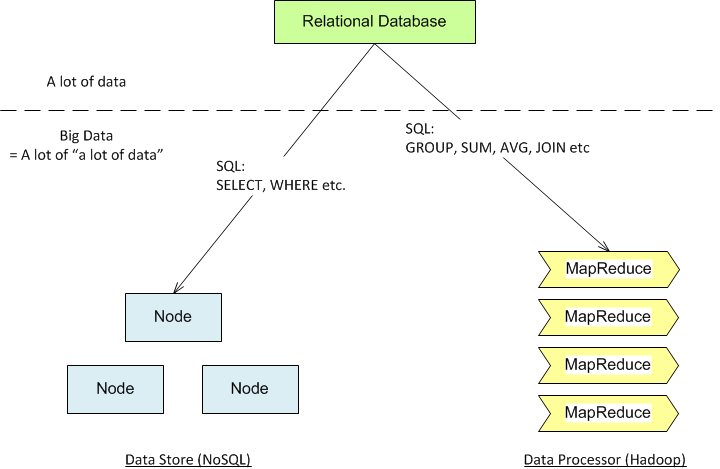
Relationship among RDMS, NoSQL and MapReduce
For a lot of data
RDMS (PostgreSQL, MySQL etc.) can handles storing / retrieval of large data set very well. It also provides basic aggregate operations on the data set to give a summarize reports to the users.
For a lot of “a lot of data”:
When the size of data set increase until RDMS can’t handle it efficiently, we can use NoSQL cluster to store data. In general, most NoSQL store data together in Denormalizated form (very much like OLAP in RDMS). What it does is basically “pre-joined” the different piece of data, thus reducing expensive JOIN operation during run-time and make the reading super fast. However, If users want to do different ways of JOIN operations, or other aggregate functions, the operation become very expensive, because the data store has to run JOIN operation. Worse still, since most NoSQL do not support JOIN natively, this operation will tend to be slower than its RDMS counterpart. One solution is that we could make use of MapReduce function. MapReduce is a programming paradigm that break the huge data set into smaller piece (so it is consumable) and allows data processing in number of nodes in parallel manner. MapReduce functionality can be found in Hadoop. A lot of NoSQL datastores, like MongoDB or Riak, provide certain level of native MapReduce implementation too.