The Magical Bloom Filter
What is Bloom Filter?
Bloom Filter checks if a key exists or not. It was invented by Burton Bloom (and hence the name) to solve dictionary problem. The Bloom Filter is used to check if the word is in dictionary or not. Computer memory is very limited at that time, and it is impossible to load all the words into memory.
The uniqueness of Bloom Filter is that it is not a very accurate filter. If it reports false (not exist), the items definitely is not exist. However if it reports true (exist), there are a small chance that it could be false positive result.
Comparison with normal filter
To illustrate the benefit of Bloom Filter, we use a normal filter to do comparison. These filter basically do two things, store keys, and check if particular string exists or not.
public interface IFilter {
public void addData(String key);
public boolean isExist(String key);
}
Snippet 1: IFilter interface contains only 2 operations.
public class NormalFilter implements IFilter {
private HashSet keySet = new HashSet();
@Override
public void addData(String key) {
keySet.add(key);
}
@Override
public boolean isExist(String key) {
return keySet.contains(key);
}
}
Snippet 2: Normal Filter store each key, thus it size will increase with the number of keys.
public class BloomFilter implements IFilter {
private int bloomBitArray;
@Override
public void addData(String key) {
int hashKey = hash(key);
System.out.println("bloomBitArray (before):\t" + toBinaryString(bloomBitArray));
System.out.println("hashKey:\t\t" + toBinaryString(hashKey));
bloomBitArray = hashKey | bloomBitArray;
System.out.println("bloomBitArray (after):\t" + toBinaryString(bloomBitArray));
}
@Override
public boolean isExist(String key) {
int hashKey = hash(key);
System.out.println("bloomBitArray:\t" + toBinaryString(bloomBitArray));
System.out.println("hashKey:\t" + toBinaryString(hashKey));
return (bloomBitArray & hashKey) == hashKey;
}
// it can be 1 or more hash functions
private int hash(String key) {
// you can use your own hash code, even as simple as modulo hash code,
// I use Java built-in hashcode to illustrate the purpose.
// set up 1 bit in the bloomBitArray
return 1 << key.hashCode();
}
// beautify the result
private String toBinaryString(int key) {
return padLeft(Integer.toBinaryString(key));
}
// beautify the result
private String padLeft(String binaryString) {
return String.format("%32s", binaryString).replace(" ", "0");
}
}
Snippet 3: Bloom Filter doesn’t store any keys. It only stores combined hash values.
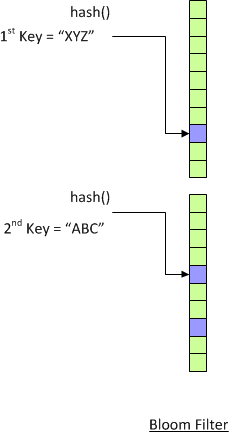
Bloom Filter stores combined hash values
public class Main {
private static IFilter filter = new BloomFilter();
//private static IFilter filter = new NormalFilter();
/**
* @param args
*/
public static void main(String[] args) {
// add as much data as you want here here
printAddData("hello");
printAddData("I");
printAddData("am");
printAddData("happy");
System.out.println("==================================================");
System.out.println(" RESULT ");
System.out.println("==================================================");
// testing
printIsExist("world");
printIsExist("wo");
printIsExist("w");
printIsExist("happy");
printIsExist("hap");
printIsExist("I");
}
private static void printAddData(String key) {
System.out.println("---------------------------------");
System.out.println("addData(" + key + ")");
filter.addData(key);
}
private static void printIsExist(String key) {
System.out.println("---------------------------------");
System.out.println("isExist(" + key + "):\t" + filter.isExist(key));
}
}
Results
---------------------------------
addData(hello)
bloomBitArray (before): 00000000000000000000000000000000
hashKey: d 00000000000001000000000000000000
bloomBitArray (after): 00000000000001000000000000000000
---------------------------------
addData(I)
bloomBitArray (before): 00000000000001000000000000000000
hashKey: d 00000000000000000000001000000000
bloomBitArray (after): 00000000000001000000001000000000
---------------------------------
addData(am)
bloomBitArray (before): 00000000000001000000001000000000
hashKey: d 00000000000000000001000000000000
bloomBitArray (after): 00000000000001000001001000000000
---------------------------------
addData(happy)
bloomBitArray (before): 00000000000001000001001000000000
hashKey: d 00000000000000000000000000000001
bloomBitArray (after): 00000000000001000001001000000001
==================================================
RESULT
==================================================
---------------------------------
bloomBitArray: 00000000000001000001001000000001
hashKey: 00000000000001000000000000000000
isExist(world): true
---------------------------------
bloomBitArray: 00000000000001000001001000000001
hashKey: 00000001000000000000000000000000
isExist(wo): false
---------------------------------
bloomBitArray: 00000000000001000001001000000001
hashKey: 00000000100000000000000000000000
isExist(w): false
---------------------------------
bloomBitArray: 00000000000001000001001000000001
hashKey: 00000000000000000000000000000001
isExist(happy): true
---------------------------------
bloomBitArray: 00000000000001000001001000000001
hashKey: 00000000100000000000000000000000
isExist(hap): false
---------------------------------
bloomBitArray: 00000000000001000001001000000001
hashKey: 00000000000000000000001000000000
isExist(I): true
Snippet 5: Bloom Filter Test Result
Note that the first result “world” is not correct. This is the “uniqueness” Bloom Filter (Yea, when we love something, we will call whatever defects as uniqueness :D).
So the “special” character of Bloom Filter is:
- When it say “wrong”, it is definitely wrong.
- When it say “right”, it could be right, or it could be wrong (false positive).
As the result, we can trust the result when it says “something doesn’t exist”. If it reports “yes, it exists”, we will have to check in other way to confirm the result. It seems like problematic, but in fact it is not, because Bloom Filter is normally used as an add-on to speed up query. It doesn’t stand alone.
Benefits
Size does matter
As you can see, Bloom Filter stores only hash values. Each has values will be “OR”ed with current bit array in Bloom Filter, as the result, the size of Bloom Filter remains constant, regardless the number of input.
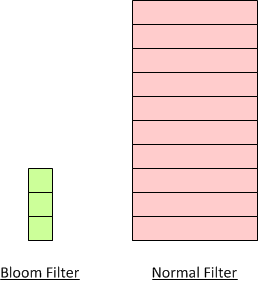
Bloom Filter size comparison
Increase query speed
Several NoSQL datastores, namely HBase and Cassandra, have use it to increase query speed.
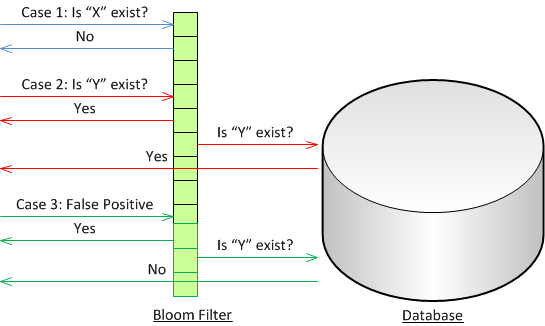
Bloom Filter in database
Assuming checking with Bloom Filter takes 1 ms, and querying with database takes 100 ms.
We have 3 cases here.
- Case 1: If Bloom Filter reports that the item doesn’t exist, the operation takes 1 ms.
- Case 2: If Bloom filter reports that the item exists, the request will be sent to database, and database will return the data, the operation takes 1 + 100 ms = 101 ms
- Case 3: If Bloom filter reports that the item exists, the request will be sent to database, and database will report not found, the operation takes 1 + 100 ms = 101 ms
Source code: blog-bloomfiter.zip