Who Will Be Your Next Friend?
Triadic Closure
Given 3 people – A, B and C, If A and B are friends, B and C are friends, there is high possibility that A and C are friends, or will be friends. If each person can be represented as a node, 3 nodes form a Triadic Closure.
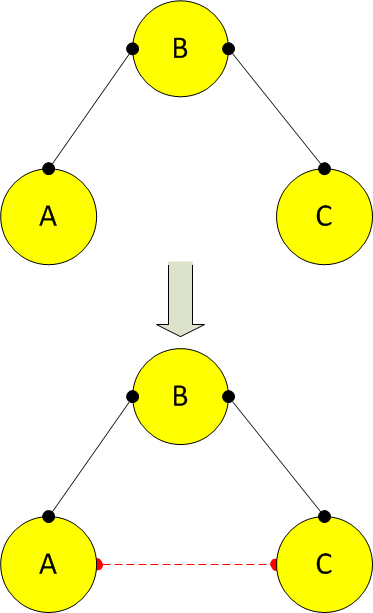
Triadic Closure
Example</h2>
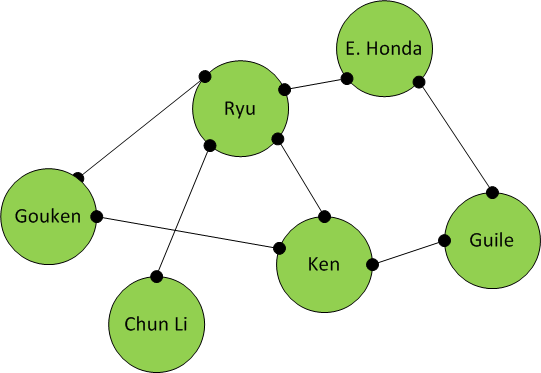
Character Relationship Chart
Given a character relationship chart, we want to find out who Ken will be friend with next. We can use Neo4j for this analysis.
First We store the relationship into Neo4j using Cypher language.
CREATE gouken = {id:1, name:"Gouken"},
chunLi = {id:2, name:"Chun Li"},
ken = {id:3, name:"Ken"},
ryu = {id:4, name:"Ryu"},
eHonda = {id:5, name:"E. Honda"},
guile = {id:6, name:"Guile"};
START n1 = node:node_auto_index(name = "Gouken"), n2 = node:node_auto_index(name = "Ryu")
CREATE (n1)-[:FRIEND]-(n2);
START n1 = node:node_auto_index(name = "Gouken"), n2 = node:node_auto_index(name = "Ken")
CREATE (n1)-[:FRIEND]-(n2);
START n1 = node:node_auto_index(name = "Ryu"), n2 = node:node_auto_index(name = "Ken")
CREATE (n1)-[:FRIEND]-(n2);
START n1 = node:node_auto_index(name = "Ryu"), n2 = node:node_auto_index(name = "Chun Li")
CREATE (n1)-[:FRIEND]-(n2);
START n1 = node:node_auto_index(name = "Ryu"), n2 = node:node_auto_index(name = "E. Honda")
CREATE (n1)-[:FRIEND]-(n2);
START n1 = node:node_auto_index(name = "E. Honda"), n2 = node:node_auto_index(name = "Guile")
CREATE (n1)-[:FRIEND]-(n2);
START n1 = node:node_auto_index(name = "Ken"), n2 = node:node_auto_index(name = "Guile")
CREATE (n1)-[:FRIEND]-(n2);
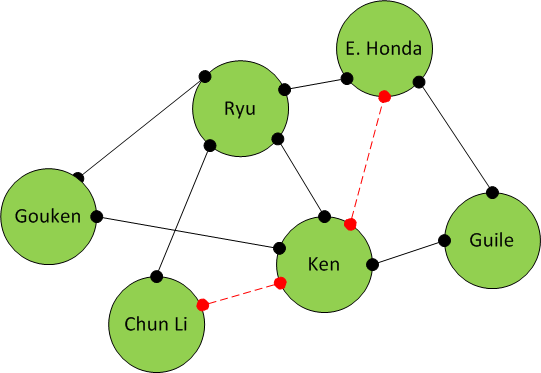
Character Relationship Chart with Possible Link
To find out who will be Ken’s next friend, we can run a query to find all incomplete Triadic Closures:
START ken = node:node_auto_index(name = "Ken") MATCH (ken)-[:FRIEND]-(commonFriend)-[:FRIEND]-(stranger)-[rel?:FRIEND]-(ken) WHERE rel is null RETURN distinct ken.name, stranger.name;
Result:
==> +--------------------------+ ==> | ken.name | stranger.name | ==> +--------------------------+ ==> | "Ken" | "E. Honda" | ==> | "Ken" | "Chun Li" | ==> +--------------------------+
From the result, we know that Ken has high probability to be friend with E. Honda and Chun Li, because they both have common friends.
The more common friends they share, the higher chance they will be friend eventually. To find out who will have higher chances to be friend with Ken, we can run a query to find out the number of common friends they share with Ken:
START ken = node:node_auto_index(name = "Ken") MATCH (ken)-[:FRIEND]-(commonFriend)-[:FRIEND]-(stranger)-[rel?:FRIEND]-(ken) WHERE rel is null RETURN distinct ken.name, stranger.name, count(commonFriend);
Result:
==> +------------------------------------------------+ ==> | ken.name | stranger.name | count(commonFriend) | ==> +------------------------------------------------+ ==> | "Ken" | "E. Honda" | 2 | ==> | "Ken" | "Chun Li" | 1 | ==> +------------------------------------------------+
Ken and E. Honda’s common friends are Ryu and Guile, whereas with Chun Li, their common friend is Ryu only. From the result, we know that Ken will have higher chance to be friend with E. Honda.